
Durchsuchbare PDF-Datei mittels OCR erstellen
Funktion für die Erstellung einer durchsuchbaren PDF-Datei
Beim Umwandeln gescannter Originaldaten in PDF-Dateien fügen Sie transparente Textdaten in eine PDF-Datei ein und erstellen eine durchsuchbare PDF-Datei. Mit dieser Funktion werden automatisch mit Hilfe von Zeichenerkennungstechnologien Textinformationen von gescannten Bildern erstellt.
Die folgende Aufstellung zeigt die Originaltextgrößen, die von diesem System erkannt werden können.
Bei einer Auflösung von 200 dpi
Japanisch: 12 Punkte bis 142 Punkte
Europäische und amerikanische Sprachen: 9 Punkte bis 142 Punkte
Asiatische Sprachen: 20 Punkte bis 142 Punkte
Bei einer Auflösung von 300 dpi
Japanisch: 8 Punkte bis 96 Punkte
Europäische und amerikanische Sprachen: 6 Punkte bis 96 Punkte
Asiatische Sprachen: 12 Punkte bis 96 Punkte

Für die Verwendung dieser Funktion wird eine Zubehörkomponente benötigt. Ausführliche Informationen zu den erforderlichen Zubehörkomponenten finden Sie Hier.
In folgenden Fällen werden Textdaten möglicherweise nicht korrekt erkannt:
Im Original wird auf dem Multifunktionssystem nicht unterstützter Text verwendet.
Es wurde eine vom Original abweichende Sprache gewählt.
Die Originalausrichtung entspricht nicht der Textrichtung, wenn die Seitenausrichtung nicht automatisch angepasst wird.
Erstellen einer durchsuchbaren PDF-Datei
Zum Senden einer PDF-Datei erstellen Sie eine durchsuchbare PDF-Datei mithilfe von OCR-Zeichenerkennungstechnologie.
Zum Erstellen einer durchsuchbaren PDF-Datei wählen Sie [PDF] oder [Kompaktes PDF] als Dateityp und wählen dann [PDF-Detaileinstellung] - [Durchsuchbare PDF]. Richten Sie anschließend die folgenden Einstellungen ein.
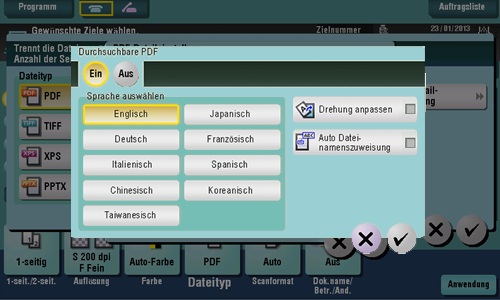
Einstellung | Beschreibung |
|---|---|
[EIN]/[AUS] | Wählen Sie [EIN], um eine durchsuchbare PDF-Datei zu erstellen. |
[Sprache auswählen] | Wählen Sie eine Sprache für die OCR-Verarbeitung. Wählen Sie die im Original verwendete Sprache, um die ordnungsgemäße Erkennung der Textdaten sicherzustellen. |
[Drehung anpassen] | Setzen Sie diese Option auf EIN, um die Drehung automatisch für jede Seite basierend auf der Ausrichtung der bei der OCR-Verarbeitung erkannten Textdaten vorzunehmen. Wenn die Anpassung der Drehung deaktiviert ist und die angegebene Ausrichtung des Originals nicht mit der Textausrichtung übereinstimmt, werden die Textdaten nicht ordnungsgemäß erkannt. |
[Automatische Dateinamenszuweisung] | Setzen Sie diese Option auf EIN, um eine Zeichenfolge, die sich aufgrund des Ergebnisses der OCR-Zeichenerkennung als Dokumentname eignet, automatisch zu exportieren und als Dokumentnamen festzulegen. Ein Dokumentname wird auf der Basis des Zeichenerkennungsergebnisses der ersten Seite, der Angaben für Datum und Uhrzeit und der Seriennummer automatisch zugewiesen. |
Durch Auswahl von [Kompaktes PDF] als [Dateityp] erhalten Sie eine höhere OCR-Verarbeitungsgeschwindigkeit als bei Auswahl von [PDF].
[Drehung anpassen] ist nicht verfügbar, wenn gleichzeitig die Verschlüsselung mit einem digitalen Zertifikat (digitale ID) aktiviert ist.
Wenn [PDF/A] auf [PDF/A-1a] eingestellt ist, ist die Einstellung für durchsuchbares PDF nicht verfügbar.
Wenn unter [Sprache auswählen] die folgende Sprache ausgewählt ist, wird die Textausrichtung automatisch erkannt.
[Japanisch], [Vereinfachtes Chinesisch], [Koreanisch], [Traditionelles Chinesisch]Wenn [Sprache auswählen] ausgewählt ist und auf derselben Seite des Originals sowohl eine vertikale als auch eine horizontale Ausrichtung vorhanden ist, wird nur eine dieser beiden Ausrichtungen erkannt.
[Vereinfachtes Chinesisch], [Koreanisch], [Traditionelles Chinesisch]

