
Creación de un archivo PDF en el que se puedan realizar búsquedas mediante OCR
Función de PDF en el que se puede buscar
Al convertir los datos escaneados de un original en un archivo de formato PDF, pegue datos de texto transparente en el archivo PDF y, a continuación, cree un archivo PDF en el que se puedan realizar búsquedas. Esta función crea automáticamente información de texto de las imágenes escaneadas utilizando la tecnología de reconocimiento de caracteres OCR.
La tabla siguiente muestra los tamaños de texto de un original que esta máquina puede reconocer.
Cuando la resolución es de 200 ppp
Japonés: 12 pt a 142 pt
Idiomas europeos y americanos: 9 pt a 142 pt
Idiomas asiáticos: 20 pt a 142 pt
Cuando la resolución es de 300 ppp
Japonés: 8 pt a 96 pt
Idiomas europeos y americanos: 6 pt a 96 pt
Idiomas asiáticos: 12 pt a 96 pt

Para utilizar esta función, se requiere una opción adicional. Para obtener más información sobre la opción necesaria, consulte Aquí.
Los datos de texto puede que no se reconozcan correctamente si:
en el original se utiliza texto no admitido en el MFP.
Se selecciona un idioma distinto al del original.
La orientación del original no es la misma que la dirección del texto cuando la orientación de la página no se ha ajustado automáticamente.
Creación de un archivo PDF en el que se puede buscar
Al enviar un archivo PDF, cree un archivo en el que se pueden realizar búsquedas utilizando la tecnología de reconocimiento óptico de caracteres (OCR).
Para crear un archivo PDF en el que se puedan realizar búsquedas, seleccione [PDF] o [PDF compacto] como tipo de archivo y seleccione [Config. detallada de PDF] - [PDF en el que se puede buscar]. A continuación, configure las siguientes opciones.
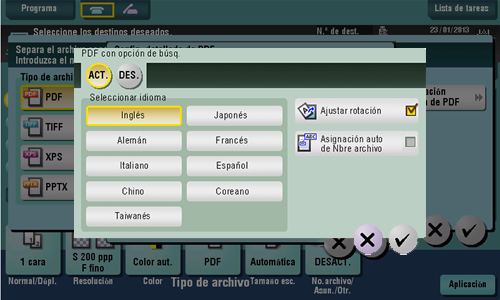
Configuración | Descripción |
|---|---|
[ACT.]/[DES.] | Seleccione [ACT.] para crear un archivo PDF en el que se pueden realizar búsquedas. |
[Seleccionar idioma] | Seleccione un idioma para el procesamiento OCR. Seleccione el idioma utilizado en el original para reconocer correctamente los datos de texto. |
[Ajustar rotación] | Asigne a esta opción el valor ON para llevar a cabo automáticamente el ajuste de la rotación de cada página basándose en la dirección de los datos de texto detectados por el procesamiento OCR. Al deshabilitar el ajuste de la rotación, si la orientación especificada del original no corresponde con la dirección del texto, los datos de texto no se reconocen correctamente. |
[Asignación auto de Nbre archivo] | Asigne a esta opción el valor ON para exportar automáticamente una cadena de caracteres apropiada como nombre de documento, a partir del resultado del reconocimiento óptico de caracteres y especificarla como nombre de documento. A un documento se le asigna automáticamente un nombre a partir del resultado del reconocimiento óptico de caracteres de la primera página, fecha, hora y número de serie. |
Seleccionar [PDF compacto] como [Tipo archivo] puede ofrecer una velocidad de OCR más alta que [PDF].
[Ajustar rotación] no está disponible cuando se activa junto con el cifrado con certificado digital (ID digital).
Si [PDF/A] tiene el valor [PDF/A-1a], la configuración de PDF con función de búsqueda no está disponible.
Si se seleccionan los siguientes idiomas en [Seleccionar idioma], la dirección del texto se reconoce de forma automática.
[Japonés], [Chino (simplificado)], [Coreano], [Chino (tradicional)]Al seleccionar [Seleccionar idioma], si están mezcladas en la misma página de un original direcciones vertical y horizontal, se reconocen como una dirección.
[Chino (simplificado)], [Coreano], [Chino (tradicional)]

