
Creazione di un file PDF reperibile tramite OCR
Funzione PDF reperibile
Quando si convertono i dati di un originale scansionato nel formato PDF, incollare i dati del testo trasparente in un file PDF, quindi creare un file PDF ricercabile). Questa funzione crea automaticamente le informazioni di testo da immagini scansionate grazie alla tecnologia di riconoscimento dei caratteri OCR.
Di seguito sono elencati i formati di testo originale riconoscibili da questa macchina.
Quando la risoluzione è pari a 200 dpi
Giapponese: da 12 pt a 142 pt
Lingue europee e americane: da 9 pt a 142 pt
Lingue asiatiche: da 20 pt a 142 pt
Quando la risoluzione è pari a 300 dpi
Giapponese: da 8 pt a 96 pt
Lingue europee e americane: da 6 pt a 96 pt
Lingue asiatiche: da 12 pt a 96 pt

Per utilizzare questa funzione è necessaria un'opzione. Per dettagli sull'opzione richiesta, fare riferimento a Qui.
I dati in formato testo potrebbero non essere riconosciuti correttamente quando:
nell'originale è utilizzato un testo non supportato nella MFP.
È stata selezionata una lingua diversa da quella dell'originale.
L'orientamento dell'originale non coincide con la direzione del testo quando l'orientamento della pagina non è regolato automaticamente.
Creazione di un file PDF reperibile
Quando si invia un file PDF reperibile, creare un file PDF ricercabile utilizzando la tecnologia di riconoscimento dei caratteri OCR.
Per creare un PDF reperibile, selezionare [PDF] o [PDF compatto] come tipo di file, quindi selezionare [Impostazioni PDF dettagl.] - [PDF reperibile]. Successivamente, configurare le seguenti impostazioni.
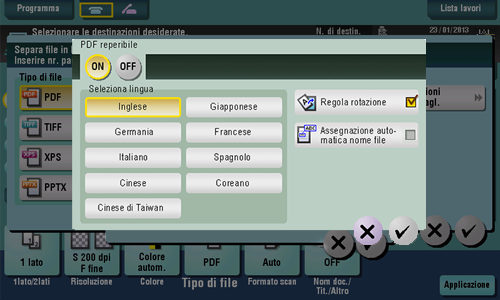
Impostazione | Descrizione |
|---|---|
[ON]/[OFF] | Selezionare [ON] per creare un file PDF reperibile. |
[Impostazione lingua] | Selezionare una lingua per l'elaborazione OCR. Selezionare la lingua utilizzata nell'originale per riconoscere correttamente i dati di testo. |
[Regola rotazione] | Impostare quest'opzione su ON per eseguire automaticamente la regolazione della rotazione per ciascuna pagina in base alla direzione dei dati di testo rilevati dall'elaborazione OCR. Quando la regolazione della rotazione è disattivata, se l'orientamento originale specificato non corrisponde alla direzione del testo, i dati testo non saranno riconosciuti correttamente. |
[Estrazione auto nome documento] | Impostare quest'opzione su ON per esportare automaticamente, dai risultati di riconoscimento del carattere OCR, una stringa di caratteri appropriati come nome del documento e specificarla come nome documento. Il nome documento è assegnato automaticamente in base ai risultati del riconoscimento caratteri della prima pagina, della data, l'ora e il numero di serie. |
La selezione di [PDF compatto] per il [Tipo di file] può offrire una velocità di elaborazione OCR più elevata rispetto all'opzione [PDF].
[Regola rotazione] non è disponibile quando è attiva la crittografia per mezzo di un certificato digitale (ID digitale).
Quando [PDF/A] è impostato su [PDF/A-1a], l'impostazione PDF ricercabili non è disponibile.
Se la seguente lingua è visualizzata in [Impostazione lingua], la direzione testo è riconosciuta automaticamente.
[Giapponese], [Cinese], [Coreano], [Cinese di Taiwan]Quando è selezionato [Impostazione lingua], se le direzioni verticali e orizzontali sono miste nella stessa pagina di un originale, saranno riconosciute come un'unica direzione.
[Cinese semplificato], [Coreano], [Cinese tradizionale]

